Sounds great in theory, but what about reality?
Part Two (P1 click here) of the discovery process is focused on looking at (auditing) real-world implementation of product recommender systems in various products and services.
Google search for any service or site for “best recommendation system website or app” and you will inevitably see the following on the list, somewhere near the top:
- Spotify
- Netflix
- Hulu
The aforementioned streaming media companies ARE the most often mentioned example of a “Personalized Recommendation System” that gets “it” right (“it” being whatever the user deems it to be with regard to personalization); nearly everyone I’ve spoken to holds them up as a positive example of a correctly implemented and working system. Netflix is a slightly different use case in that they had user profiles and preferences from their red mailer days, compared to Spotify.
Since these platforms are so often mentioned for their product recommendation systems, so often listed, so talked about and discussed, algorithms dissected, I’ll not go into too much depth on their observed strategies and displays.
For the quantitative-oriented, the all up numbers for the audit are:
- 18 comparative brands
- 26+ tags (e.g., “Signal type”, “User status”, “Inputs”, “Platform” etc)
- 200+ screens across app and web
- Streaming media
- Publishing
- E-commerce retail & marketplace
- Social media
- Ride share
- Specialty/curated
Comparative Audits
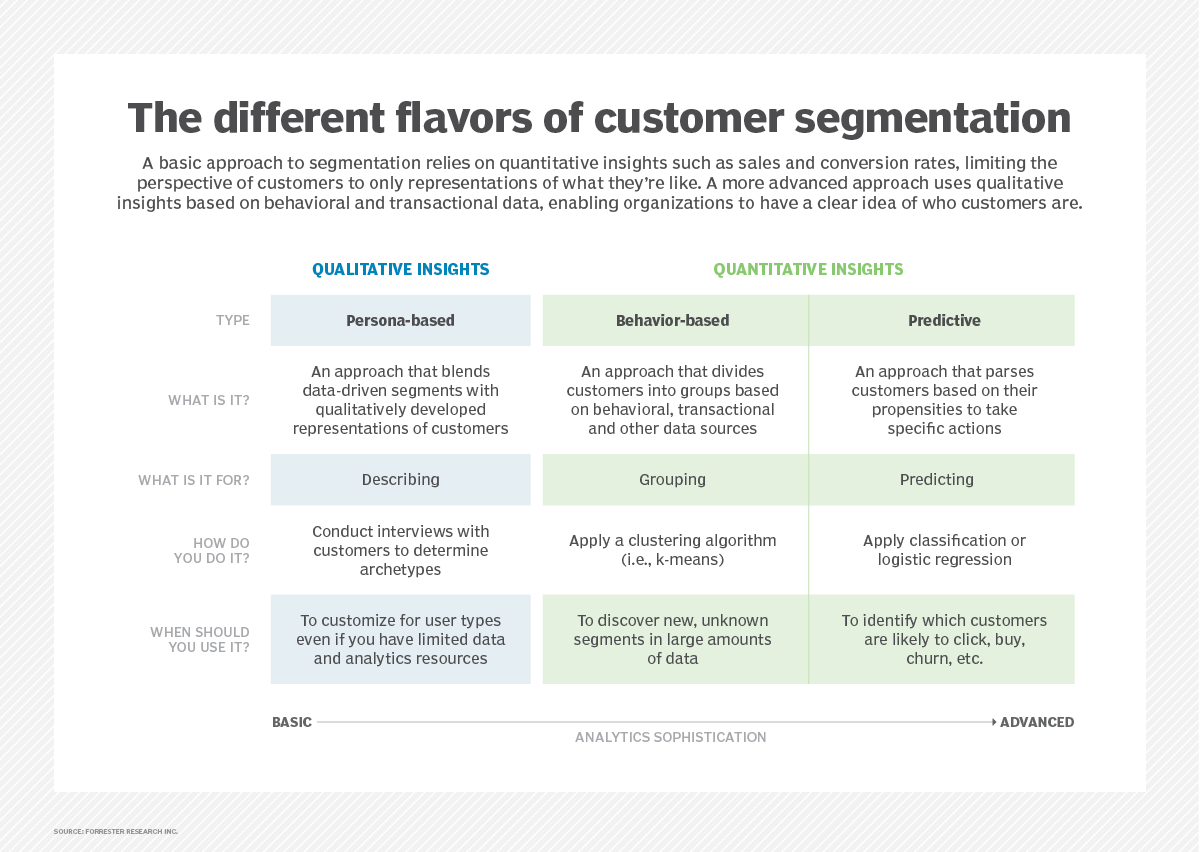
What is a comparative audit and why do we do it?
User experience professionals conduct comparative audits in order to understand the problem/solution space being investigated. We often look for and capture competitive experiences (if applicable) BUT equally as important we look outside the competitive landscape to gain a more holistic view and understanding of the space
In this case, with regard to product recommendations:
- Our customers browse and shop on other sites and apps; it is in our best interest to understand recommendations in those environments
- Looking at different product and service models exposes us to different types of recommendation strategies and implementations
- Auditing comparative sites gives us a more informed, broader view of product recommendation strategies that can inspire our own explorations and provide examples we can point to
Competitive audits often have the lens of the subject matter applied to them to make cogent observations. Using the content and information recorded in my research of product recommendation systems (Part 1), I created a set of specific “product recommendation” tags and created a lexicon for audit notes. It enabled me to be more aware of what I was looking for and accurately describe it. The lexicon and established vernacular proved useful for other team members because we all used the same language to identify and discuss our observations.
In this case, with regard to product recommendations, I purposefully:
- Audited for different types of recommendation strategies (global, contextual to product, personalization, custom or hyper-personalization)
- Reviewed product grain/tier, individual page location and context, content and mechanics
- Captured results of both implicit and explicit inputs, such as user type, signed in/out status, likes, searches, filters, list creation, product page views, onboarding and feedback loops
- Additionally observed changes based on frequency of visits and cross device browsing

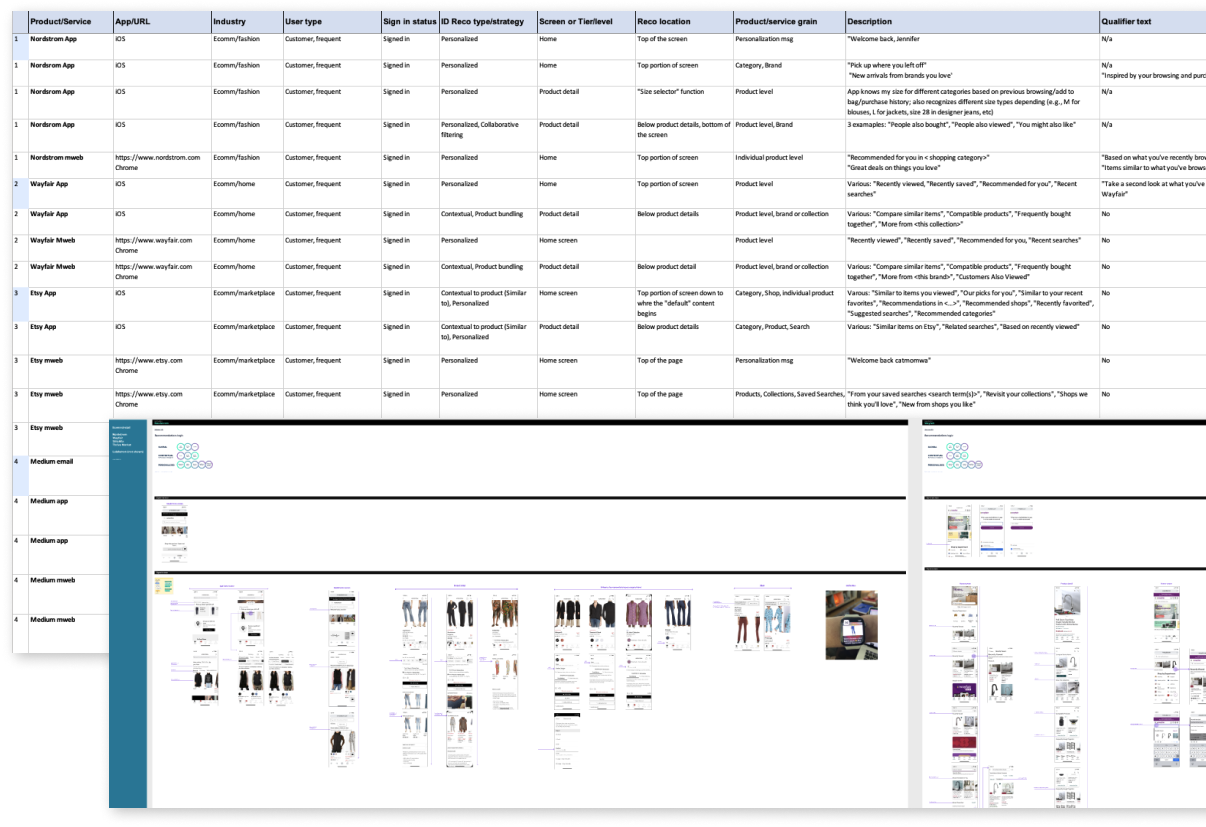
Capturing observations and flows
Information, flows and screen level observations were captured and recorded simultaneously in Excel and in Figma. I inserted both call outs at the flow and screen levels correlating to specific points of data in the spreadsheet. Both the mobile website and App experience were reviewed


Key observations

Of the 18 or so product and service companies I audited I’ll limit my observations and examples to the following:
- Nordstrom (retail fashion)
- Etsy (retail marketplace)
- Wayfair (retail home)
- Twitter (social media)
- Medium (publishing platform)
- Spotify (streaming service)
Qualifier text provides credible connection and builds confidence

Qualifying text is necessary to build trust and a logical connection between user behavior and the recommendations being provided to her. Examples of qualifying text are, per the above images “Based on your reading history”, “Selected for you”, “Based on your likes”, “Inspired by your browsing and purchase history.”
- Medium and Twitter provide contextual qualifiers at both article and tweet level respectively when applicable and appropriate
- Nordstrom was the only retailer who provided qualifier text with recommended products on the home screen
User feedback functions facilitate more relevant, personalized experiences

In order to refine recommendations the system needs relevant signal from the user and ideally reason as to why the suggestions are acceptable or not acceptable. Providing feedback mechanisms in appropriate context enables the user to quickly and easily provide feedback to the content or products being displayed to her. It’s worth noting that these types of feedback controls were only visible in publishing, social media and streaming services. Retail did not have explicit controls.
- None of the retailer sites/apps provide a method for users to give direct feedback on “recommendations” or “suggestions” resulting in heavy reliance on implicit data interactions and/or less frequent explicit data sources
- Medium and Twitter platforms provide users with ability to provide content feedback at most granular level, individual articles and tweets respectively; both platforms have an “onboarding” process initially with suggestions throughout
- Medium and Twitter provide user controls in context of the current screen view; do not require the user navigating “away” to a profile or preferences section
Individual recognition sets a personal tone

One of the quickest ways to create a sense of personalization is to playback a user’s name or username. Additionally, layering in language with respect to recency, such as “Welcome back”, “Pick up where you left off” further enhances the perception of recognition. Additionally, acknowledging the time of day a user is visiting, such as “Good afternoon” in the case of the Spotify (above), which was accurate at the time of the observation.
- Only Nordstrom and Etsy display customer or user name with a greeting on the home screen; Spotify displays user name next to profile pic (paid account)
- User recognition (mentioned above) further strengthens relative context and continuity product recommendations that follow, especially, Nordstrom
- Nordstrom is the only company that acknowledges user on both App and Web experience
- Not including is a missed opportunity to provide small, simple user recognition feature that could be expanded to include time past since last visit, time of day when visiting etc
Customer recency leads content personalization on home screens

Personalization on the home screen tends to replay most recent user behavior and/or state. Replay helps orient and remind the customer of her previous goals or tasks when she last visited or used the service (HBO Max) which helps to jump start and facilitate re-engagement.
- Recommended products with personalization language appear at the top of the screen and are more likely to be based on recent user behavior (however “recent” is defined)
- Most if not all sites display one group of recommendations based on recency; most are labeled in a manner to remind the customer what she was looking at or how she was interacting, such as “Previously Viewed” “Previously Saved” “Pick up where you left off”. Products may be outwardly labeled, “Recommended for you”
- Product groupings further down the screen may be less specific and more broad in scope, such as “Suggested searches”
Product detail screens provide comparison to products, collections, or cohorts

Product-based recommendations are more common at the product detail level than explicit “personalized” recommendations.
- Product detail pages focus on same or similar products to the one being viewed such as “Similar products” or “More from this collection.” Suggestions may include at least one set that is more “relevant” to the individual, such as “Customers also <…> “
- Nordstrom was the only retailer with a variety of customer/user-centric labels across different products; simultaneously personalizing and providing product suggestions
- Nordstrom had only 1 alternative product carousel on the PDP while all other retailers had more than 1 suggestion
Small instances provide big opportunities to surprise and delight
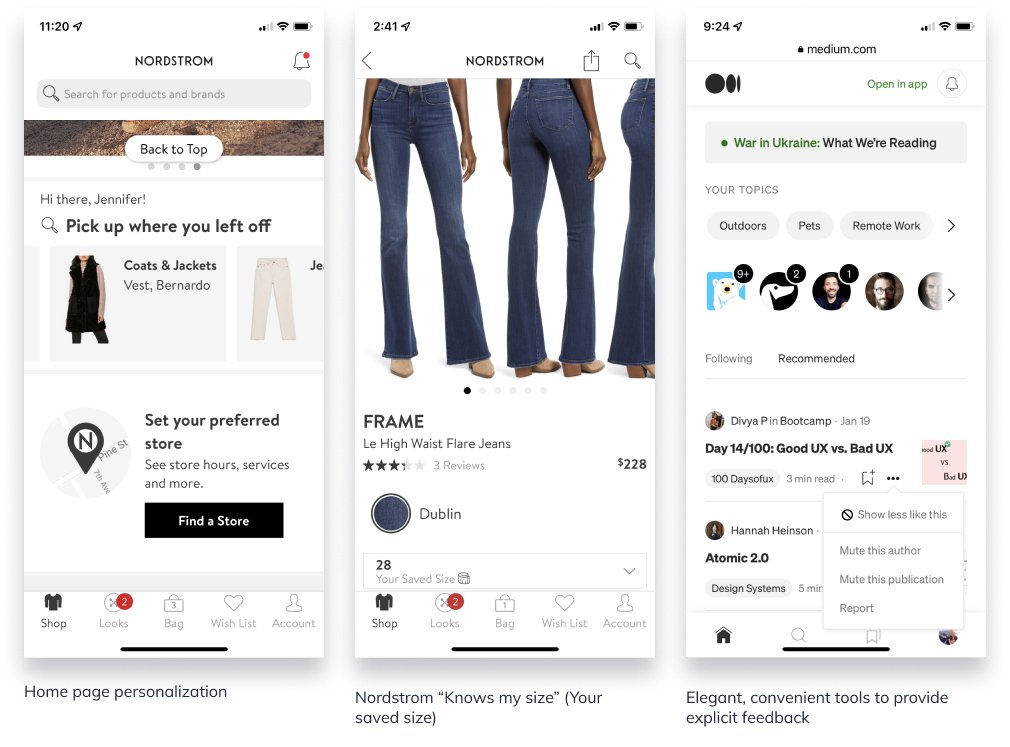
Personalization and recommendation experiences aren’t necessarily about how many different recommendation configurations can be displayed at once. Sometimes it’s the small instances that demonstrate the business is paying attention and listening.
- Home page personalization with welcoming message
- Nordstrom “Size” recommendation
Nordstrom app not only recognizes the user but also knows what size to recommend based on previous browsing and shopping. When she’s on a PDP, it will display the size she normally adds to bag/purchases. It also adjusts to category or measurement (e.g., Size M in pants, Size 28 in designer jeans) - Ability to control the display: Medium and Twitter
The ability to say “more of this” or “less of this” via an easy-to-use convenient menu gives the user more control over the content that competes for her attention and provides the business with a clearer direct signal. A win win.
In all three of these examples (exception: Welcome message), the user does not need to leave the current screen to visit a profile or preference page–these are small enough that they can be managed within the context of the current page. In the Nordstrom size example, the user never filled out a profile page for Nordstrom to indicate the different size types for all the applicable women’s categories.
Who sets the bar?
We all know about Spotify and Netflix.
Nordstrom
Designer and high-end fashion ecomm

Nordstrom brand is famous for its legendary customer service and personal shoppers. It doesn’t surprise me that the online version would follow suit where it can.
- Immediate personal recognition with display of name
- Replays previous product, at brand and category level, customer was looking at previously and provides pathway to continue browsing
- Utilizes qualifier text to qualify why the product/brand suggestions are appearing
- Auto-selects customer size and displays in size selector; applies across different types of product (NOTE: this was NEVER selected in a profile–this is learned)
- Correlates the other product suggestions with customers (“people”) like me; only one carousel of related product
Medium
Publishing platform
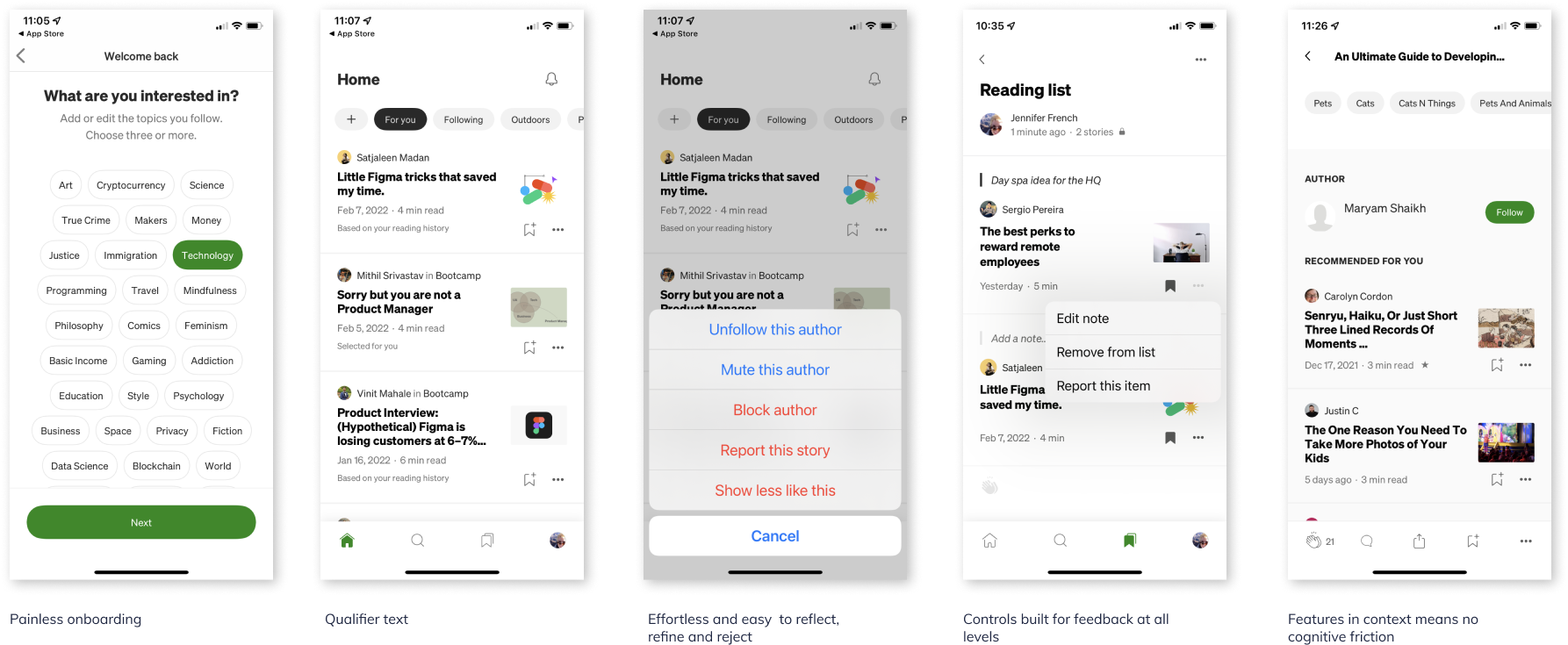
Medium’s experience is so well thought out it’s magical. It literally anticipates the user’s next-best-action across it’s various use cases and achieves what I consider to be a transparent UI.
- User centric experience from top to bottom
- From onboarding, to preferences management, to page level controls the user is able to reflect, refine and reject quickly and painlessly
- Providing feedback is effortless and does not require user to leave context in most instances
- Entire experience (language, display, interaction, algorithms) has the qualities of complete attention to detail at every touchpoint; there are no paper cuts in this experience